NSNet: Non-saliency Suppression Sampler for Efficient Video Recognition
European Conference on Computer Vision (ECCV) 2022
Boyang Xia1,2*, Wenhao Wu3,4$\dagger$*, Haoran Wang4, Rui Su5, Dongliang He4, Haosen Yang6, Xiaoran Fan1,2, Wanli Ouyang5,3
2University of Chinese Academy of Sciences 3The University of Sydney
4Baidu Inc. 5Shanghai AI Laboratory 6Harbin Institute of Technology
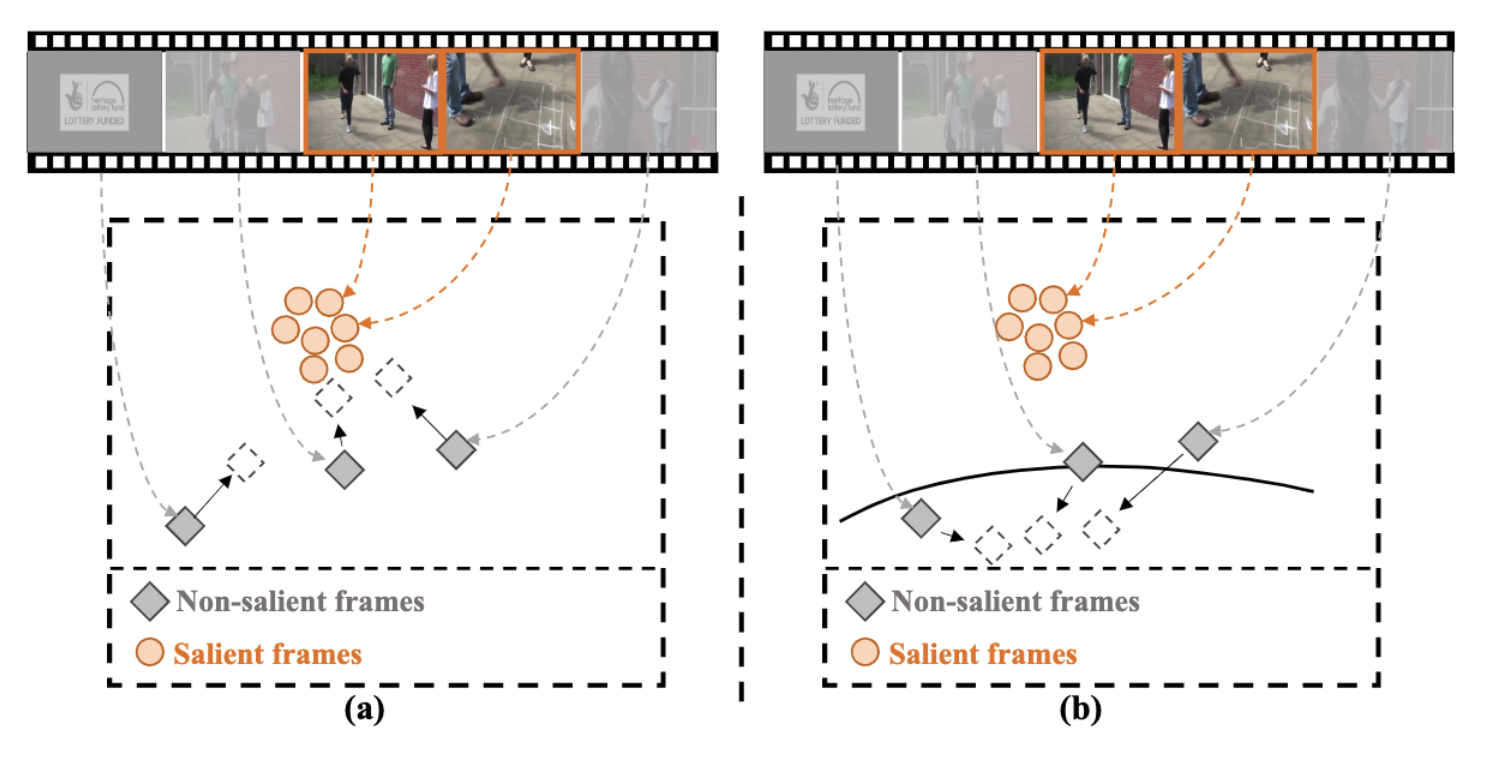
To accelerate the video recognition architectures, one typically build a lightweight video key frame sampler to firstly sample a few salient frames and then evoke a recognizer on them, to reduce temporal redundancies. However, existing methods neglect the discrimination between non-salient frames and salient ones in training objectives. We introduced a novel multi-granularity supervision scheme to suppress the non-salient frames and achieved SOTA accuracy with very low GFLOPs and wall-clock time ($4\times$ faster than SOTA methods) on 4 video recognition benchmarks.